RAG简介
LLM与RAG简介
大模型的缺点
- 知识的时效性问题:大模型存在一定的知识滞后,即大模型掌握的知识很可能是过时的,它无法回答超出其训练知识时间点之后的问题。
- 输出难以解释的“黑盒子”问题:大模型简单易用的一个重要原因来自其“黑盒”运行的模式。除了大模型的输入提示词,你无须关心,也无法观察到其内部的推理、决策与输出过程。这降低了使用者的使用门槛,但在一些深层的应用场景中会给使用者带来困惑,或者给应用开发者带来调试上的麻烦。比如,在一些关键的应用场景中,当需要对大模型输出进行精确的调试与控制时,你可能会发现除了修改 Prompt 和几个简单的推理参数,在大部分时候需要靠点“运气”,或者说,有很大的随机性。
- 输出的不确定性问题
- “幻觉”问题:
- 训练知识存在偏差。在训练大模型时输入的海量知识可能包含错误、过时,甚至带有偏见的信息。
- 过度泛化地推理。大模型尝试通过大量的语料来学习人类语言的普遍规律与模式,这可能导致“过度泛化”,即把普通的模式推理用到某些特定场景,就会产生不准确的输出。
- 理解存在局限性。大模型并没有真正“理解”训练知识的深层含义,也不具备人类普遍的常识与经验,因此可能会在一些需要深入理解与复杂推理的任务中出错。
- 缺乏特定行业与垂直领域的知识。
RAG概览
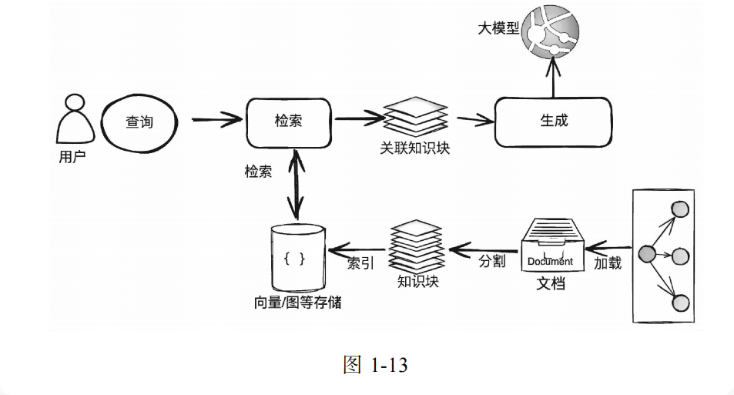
数据索引阶段
传统计算机检索技术
基于关键词的检索,比如传统的搜索引擎或者关系数据库,通过关键词的匹配程度来对知识库中的信息进行精确或模糊的检索,计算相关性,按照相关性的排序输出。
RAG
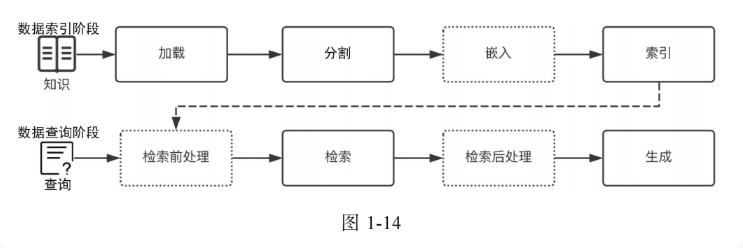
数据索引阶段
是借助基于向量的语义检索来获得相关的数据块,并根据其相似度排序,最后输出最相关的前 K 个数据块(简称top_K)。
向量
向量是一种数学表示方法,它将文本、图像、音频等复杂信息转换为高维空间中的点,每个维度都代表一种特征或属性。这种转换使得计算机可以理解和处理这些信息,因为它们都是连续的多个数值。向量保留了词汇之间的语义关系。例如,相似的词在向量空间中距离较近,这样就可以进行语义相似度计算或进行聚类分析。自然语言处理中用于把各种形式的信息转换成向量表示的模型叫嵌入模型。基于向量的语义检索就是通过计算查询词与已有信息向量的相似度(如余弦相似度),找出与查询词在语义上最接近的信息。
- 加载(Loading):RAG 应用需要的知识可能以不同的形式与模态存在,可以是结构化的、半结构化的、非结构化的、存在于互联网上或者企业内部的、普通文档或者问答对。因此,对这些知识,需要能够连接与读取内容。
- 分割(Splitting):为了更好地进行检索,需要把较大的知识内容(一个 Word/PDF 文档、一个 Excel 文档、一个网页或者数据库中的表等)进行分割,然后对这些分割的知识块(通常称为 Chunk)进行索引。当然,这就会涉及一系列的分割规则,比如知识块分割成多大最合适?在文档中用什么标记一个段落的结尾?
- 嵌入(Embedding):如果你需要开发 RAG 应用中最常见的向量存储索引,那么需要对分割后的知识块做嵌入。简单地说,就是把分割后的知识块转换为一个高维(比如 1024 维等)的向量。嵌入的过程需要借助商业或者开源的嵌入模型(Embedding Model)来完成,比如 OpenAI 的 text-embedding-3-small 模型。
- 索引(Indexing):对于向量存储索引来说,需要将嵌入阶段生成的向量存储到内存或者磁盘中做持久化存储。在实际应用中,通常建议使用功能全面的向量数据库(简称向量库)进行存储与索引。向量库会提供强大的向量检索算法与管理接口,这样可以很方便地对输入问题进行语义检索。注意:在高级的 RAG 应用中,索引形式往往并不只有向量存储索引这一种。因此,在这个阶段,很多应用会根据自身的需要来构造其他形式的索引,比如知识图谱索引、关键词表索引等。
数据查询阶段
- 存储库(比如向量库)中检索出相关知识块,并按照相关性进行排序,经过排序后的知识块将作为参考上下文用于后面的生成。
- 生成(Generation):生成的核心是大模型,可以是本地部署的大模型,也可以是基于 API 访问的远程大模型。生成器根据检索阶段输出的相关知识块与用户原始的查询问题,借助精心设计的 Prompt,生成内容并输出结果。
其他阶段
- 检索前处理(Pre-Retrieval):顾名思义,这是检索之前的步骤。在一些优化的 RAG 应用流程中,检索前处理通常用于完成诸如查询转换、查询扩充、检索路由等处理工作,其目的是为后面的检索与检索后处理做必要准备,以提高检索阶段召回知识的精确度与最终生成的质量。
- 检索后处理(Post-Retrieval):与检索前处理相对应,这是在完成检索后对检索出的相关知识块做必要补充处理的阶段。比如,对检索的结果借助更专业的排序模型与算法进行重排序或者过滤掉一些不符合条件的知识块等,使得最需要、最合规的知识块处于上下文的最前端,这有助于提高大模型的输出质量。
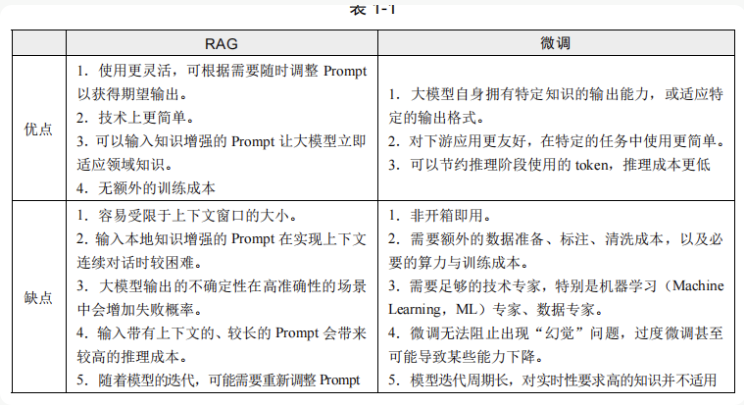
RAG与微调的对比
This post is licensed under https://creativecommons.org/licenses/by/4.0/ by the author.