Generating pipeline
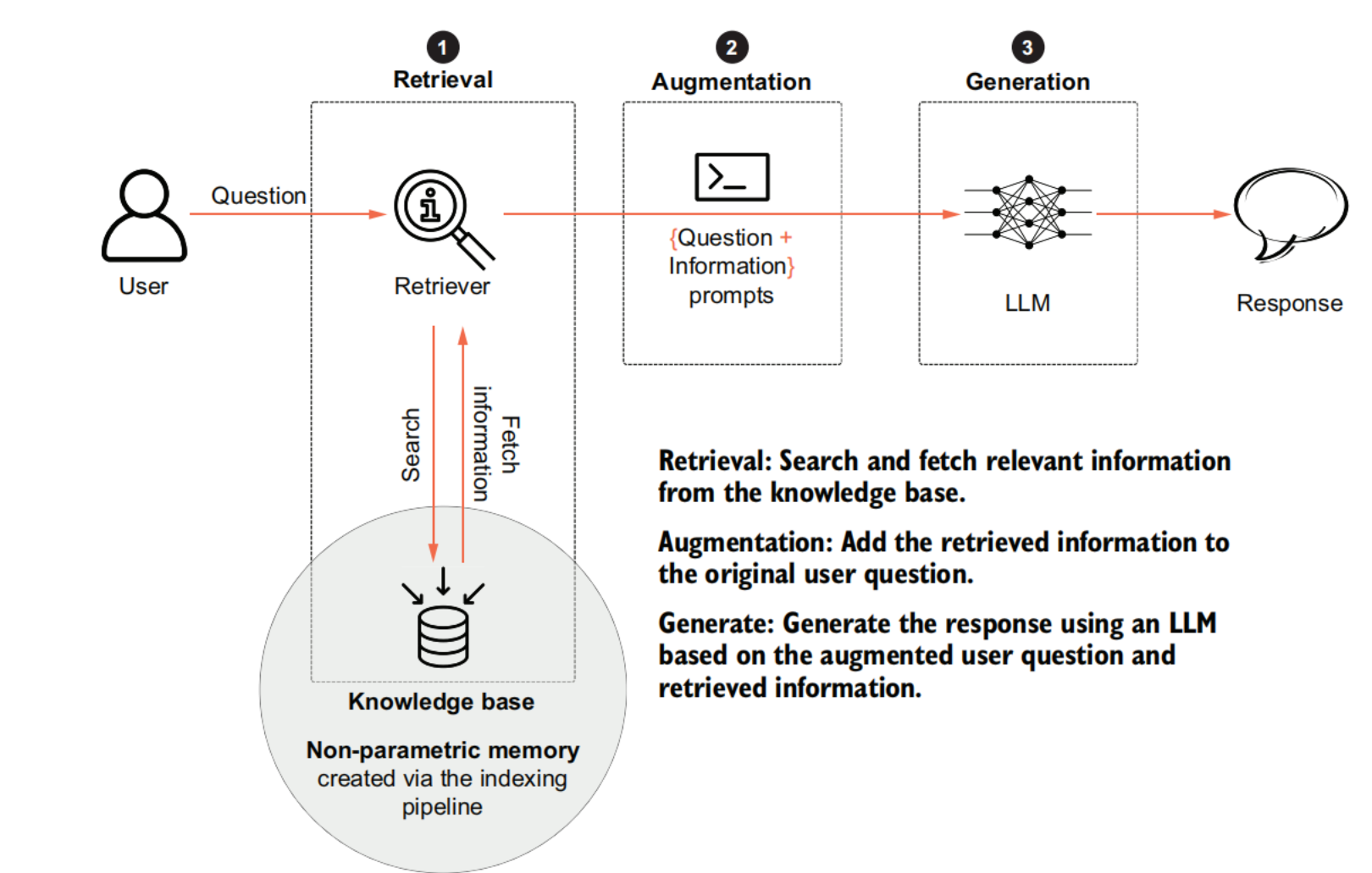
Generating contextual LLM responses
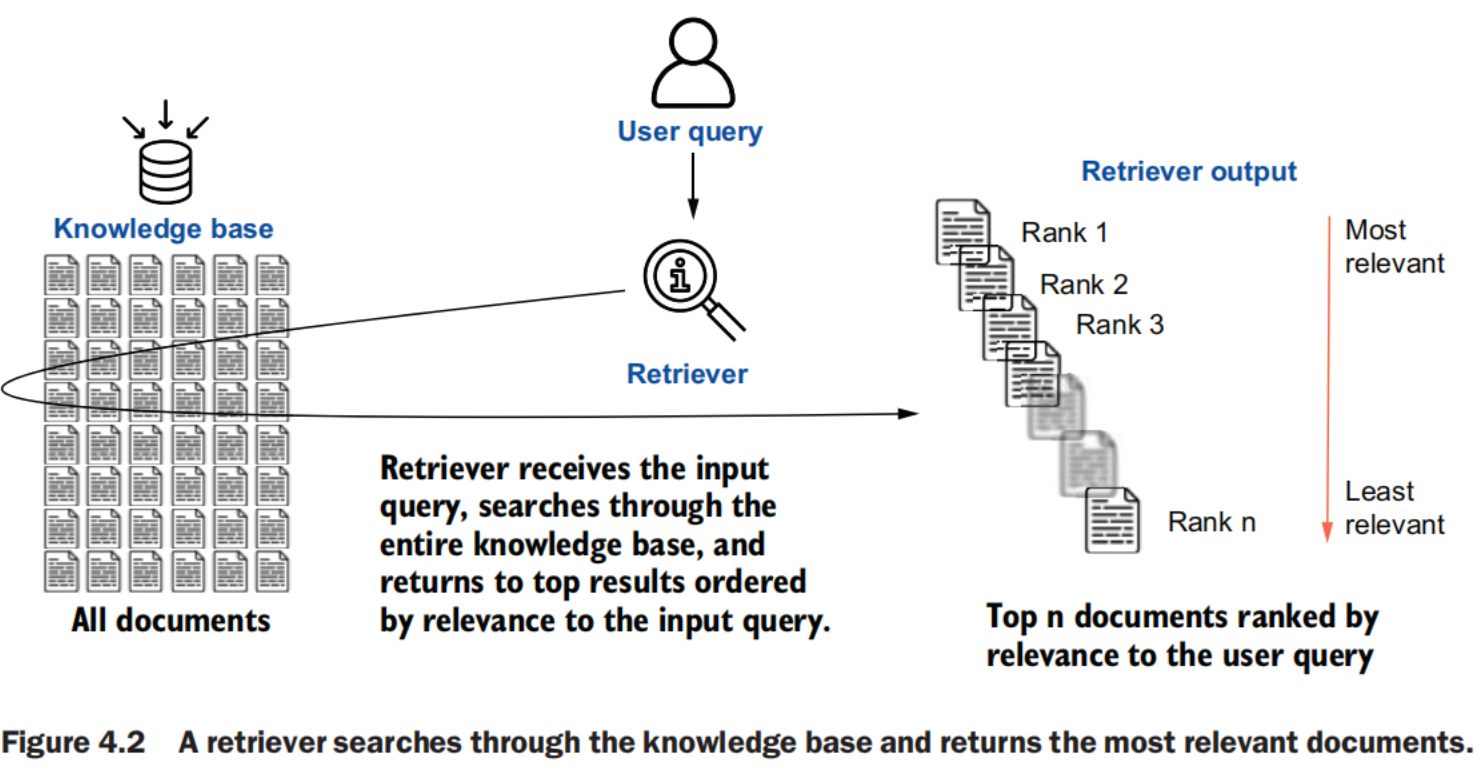
Retrieval techniques
Term Frequency–Inverse Document Frequency (TF-IDF)
TF-IDF
一个词对某篇文档越重要,它在该文档中出现得越频繁(TF 高),同时在整个语料库中越少见(IDF 高)
Term Frequency–Inverse Document Frequency (TF-IDF) is a statistical measure used to evaluate the importance of a word in a document relative to a collection of documents (corpus). It assigns higher weights to words that appear frequently in a document but infrequently across the corpus. 
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Install or Upgrade Scikit-learn
%pip install --upgrade scikit-learn
# Import TFIDFRetriever class from retrievers library
from langchain_community.retrievers import TFIDFRetriever
# Create an instance of the TFIDFRetriever with texts
retriever = TFIDFRetriever.from_texts(
["Australia won the Cricket World Cup 2023",
"India and Australia played in the finals",
"Australia won the sixth time having last won in 2015"]
)
# Use the retriever using the invoke method
result=retriever.invoke("won")
# Print the results
print(result)
TF-IDF not only can be used for unigrams, but also for phrases (n-grams). However, even TF-IDF improves on simpler search methods by emphasizing unique words, it still lacks context and word-order consideration, making it less suitable for complex tasks like RAG.
Best Match (BM25)
Best Match 25 (BM25) is an advanced probabilistic model used to rank documents based on the query terms appearing in each document. It is part of the family of probabilistic information retrieval models and is considered an advancement over the classic TF-IDF model. The improvement that BM25 brings is that it adjusts for the length of the documents so that longer documents do not unfairly get higher scores. 
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Install or Upgrade rank_bm25
%pip install –-upgrade rank_bm25
# Import BM25Retriever class from retrievers library
from langchain_community.retrievers import BM25Retriever
# Create an instance of the TFIDFRetriever with texts
retriever = BM25Retriever.from_texts(
["Australia won the Cricket World Cup 2023",
"India and Australia played in the finals",
"Australia won the sixth time having last won in 2015"]
)
# Use the retriever using the invoke method
result=retriever.invoke("Who won the 2023 Cricket World Cup?")
# Print the results
print(result)
For long queries instead of single keywords, the BM25 value is calculated for each word in the query, and the final BM25 value for the query is a summation of the values for all the words. BM25 is a powerful tool in traditional IR, but it still doesn’t capture the full semantic meaning of queries and documents required for RAG applications. BM25 is generally used in RAG for quick initial retrieval, and then a more powerful retriever is used to re-rank the results.
Static word embeddings
Static embeddings such as Word2Vec and GloVe represent words as dense vectors in a continuous vector space, capturing semantic relationships based on context. For instance, “king” − “man” + “woman” approximates “queen.” These embeddings can capture nuances such as similarity and analogy, which BoW, TF-IDF, and BM25 miss. However, while they provide a richer representation, they still lack full contextual understanding and are limited in handling polysemy (words with multiple meanings). The term static here highlights that the vector representation of words does not change with the context of the word in the input query.
Contextual embeddings
Generated by models such as BERT or OpenAI’s text embeddings, contextual embeddings produce high-dimensional, context-aware representations for queries and documents. These models, based on transformers, capture deep semantic meanings and relationships. For example, a query about “apple” will retrieve documents discussing apple the fruit, or Apple the technology company, depending on the input query. Contextual embeddings represent a significant advancement in IR, providing the context and understanding necessary for RAG tasks. Despite being computationally intensive, contextual embeddings are the most widely used retrievers in RAG.
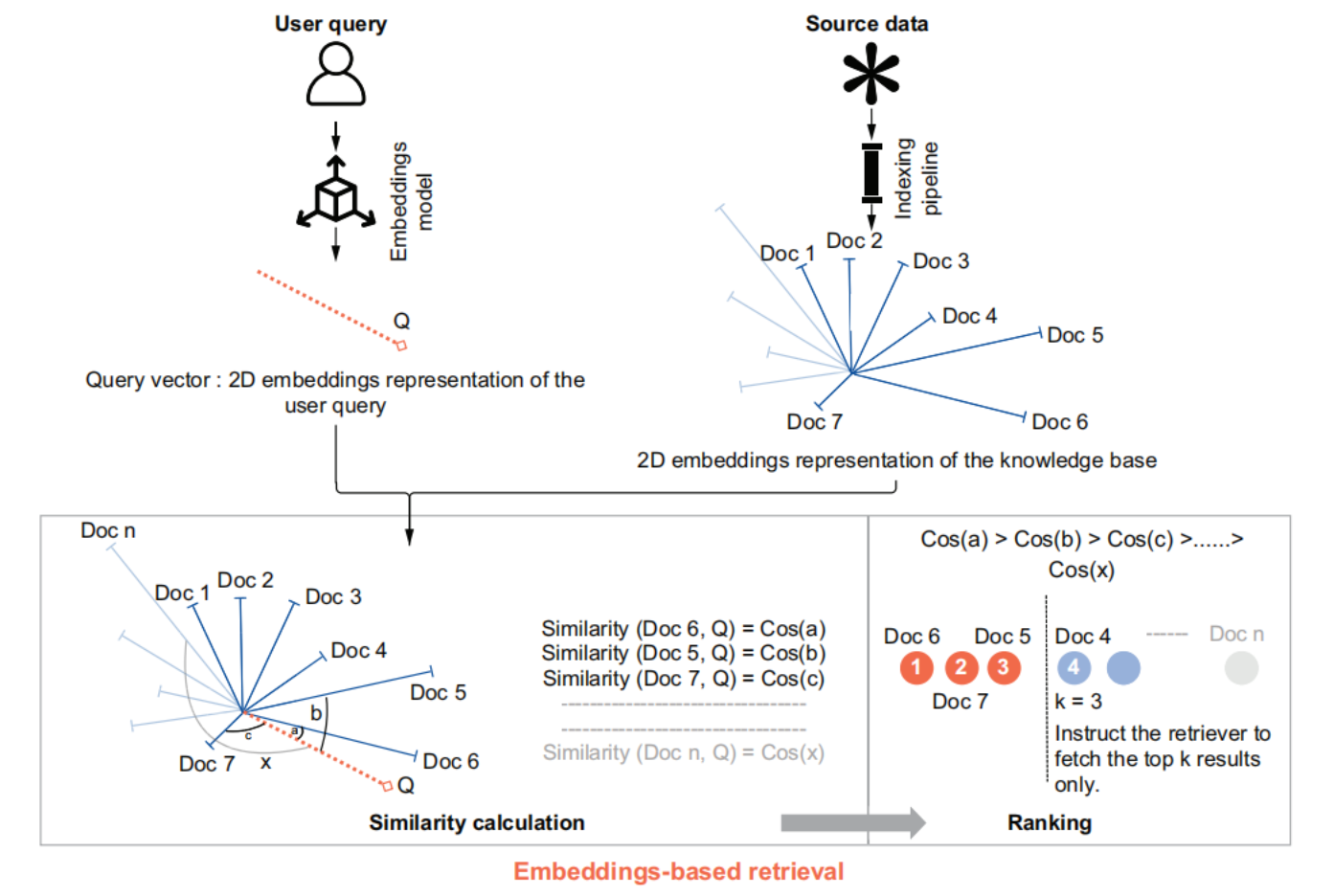
Methods such as TF-IDF and BM25 use frequency-based calculations to rank documents. In embeddings (both static and contextual), ranking is done based on a similarity score. Similarity is popularly calculated using the cosine of the angle between document vectors. 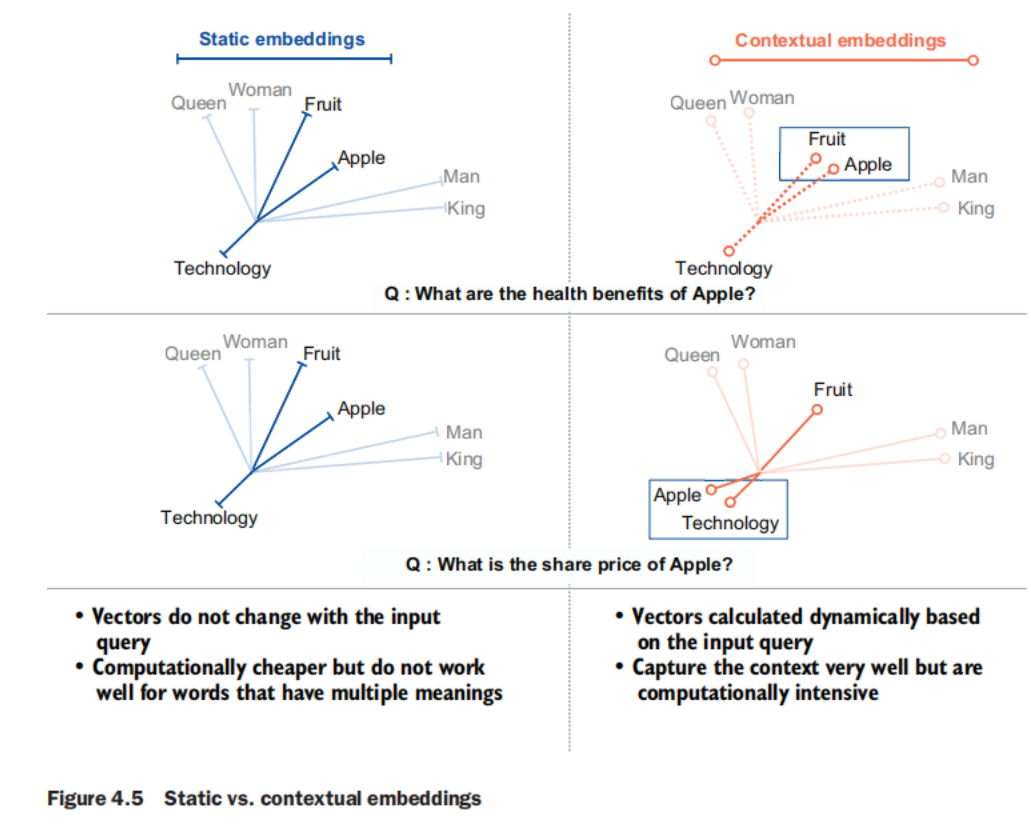
Common Retrievers
- Vector stores and databases as retrievers: Vector stores can act as the retrievers, taking away the responsibility from the developer to convert the query vector into embeddings by calculating similarity and ranking the results.
- Cloud providers: Cloud providers Azure, AWS, and Google also offer their retrievers. Integration with Amazon Kendra, Azure AI Search, AWS Bedrock, Google Drive, and Google Vertex AI Search provides developers with infrastructure, APIs, and tools for information retrieval of vector, keyword, and hybrid queries at scale.
- Web information resources: Connections to information resources such as Wikipedia, Arxiv, and AskNews provide optimized search and retrieval from these sources.
Comparison
| Technique | Key feature | Strengths | Weaknesses | Suitability for RAG |
|---|---|---|---|---|
| Boolean retrieval | Exact matching with logical operators | Simple, fast, and precise | Limited relevance ranking; no partial matching | Low: Too rigid |
| BoW | Unordered word frequency counts | Simple and intuitive | Ignores word order and context | Low: Lacks semantic understanding |
| TF-IDF | Term weighting based on document and corpus frequency | Improved relevance ranking over BoW | Still ignores semantics and word relationships | Low–medium: Better than BoW but limited; used in hybrid retrieval |
| BM25 | Advanced ranking function with length normalization | Robust performance; industry standard | Limited semantic understanding | Medium: Good baseline for simple RAG; used in hybrid retrieval |
| Static embeddings | Fixed dense vector representations | Captures some semantic relationships | Context-independent; limited in polysemy handling | Medium: Introduces basic semantics |
| Contextual embeddings | Context-aware dense representations | Rich semantic understanding; handles polysemy | Computationally intensive | High: Excellent semantic capture |
| Learned sparse retrievers | Neural-network-generated sparse representations | Efficient, interpretable, and has some semantic understanding | May miss some semantic relationships | High: Balances efficiency and semantics |
| Dense retrievers | Dense vector matching for queries and documents | Strong semantic matching | Computationally intensive; less interpretable | High: Excellent for semantic search in RAG |
| Hybrid retrievers | Combination of sparse and dense methods | Balances efficiency and effectiveness | Complex to implement and tune | High: Versatile for various RAG needs |
| Cross-encoder retrievers | Direct query-document comparison | Very accurate relevance assessment | Extremely computationally expensive | Medium–high: Great for reranking in RAG |
| Graph-based retrievers | Graph structure for document relationships | Captures complex relationships in data | Can be complex to construct and query | Medium–high: Good for structured data in RAG |
| Quantum-inspired retrievers | Quantum computing concepts in IR | Potential for handling complex queries | Emerging field; practical benefits not fully proven | Low–medium: Potentially promising but not mature |
| Neural IR models | Various neural network approaches to IR | Flexible; can capture complex patterns | Often require large training data; can be black-box | High: Adaptable to various RAG scenarios |
retriever Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Import FAISS class from vectorstore library
from langchain_community.vectorstores import FAISS
# Load the database stored in the local directory
vector_store=FAISS.load_local(
folder_path="../../Assets/Data",
index_name="CWC_index",
embeddings=embeddings,
allow_dangerous_deserialization=True
)
# Original Question
query = "Who won the 2023 Cricket World Cup?"
# Ranking the chunks in descending order of similarity
retrieved_docs = vector_store.similarity_search(query, k=2)
Augmentation
prompting
- Contextual Prompting: “Answer only based on the context provided below.” Set up our generation to focus only on the provided information and not on LLM’s internal knowledge (or parametric knowledge).
- Controlled Generation Prompting: Sometimes, the information might not be present in the retrieved document. This happens when the documents in the knowledge base do not have any informationrelevant to the user query. The retriever might still fetch some documents that are the closest to the user query. In these cases, the chances of hallucination increase because the LLM will still try to follow the instructions for answering the question. To avoid this scenario, an additional instruction is added, which tells the LLM not to answer if the retrieved document does not have proper information to answer the user question (something like, “If the question cannot be answered based on the provided context, say I don’t know.”). In the context of RAG, this technique is particularly valuable because it ensures that the model’s responses are grounded in the retrieved information. If the relevant information hasn’t been retrieved or isn’t present in the knowledge base, the model is instructed to acknowledge this lack of information rather than attempting to generate a potentially incorrect answer.”
- Few-shot Prompting: In RAG, while providing the retrieved information in the prompt, we can also specify certain examples to help guide the generation in the way we need the retrieved information to be used.

- Chain of Thought Prompting(CoT): It has been observed that the introduction of intermediate reasoning steps improves the performance of LLMs in tasks requiring complex reasoning, such as arithmetic, common sense, and symbolic reasoning. The CoT prompting approach can also be combined with the few-shot prompting technique, where a few examples of reasoning are provided before the final question. Creating these examples is a manually intensive task. In auto-CoT, the examples are also created using an LLM.

- Other Techniques:
- Self-consistency—While CoT uses a single reasoning chain in CoT prompting, self-consistency aims to sample multiple diverse reasoning paths and use their respective generations to arrive at the most consistent answer.
- Generated knowledge prompting—This technique explores the idea of prompt based knowledge generation by dynamically constructing relevant knowledge chains, using models’ latent knowledge to strengthen reasoning.
- Tree-of-thoughts prompting—This technique maintains an explorable tree structure of coherent intermediate thought steps aimed at solving problems.
- Automatic reasoning and tool use (ART)—The ART framework automatically interleaves model generations with tool use for complex reasoning tasks. ART employs demonstrations to decompose problems and integrate tools without task-specific scripting.
- Automatic prompt engineer (APE)—The APE framework automatically generates and selects optimal instructions to guide models. It uses an LLM to synthesize candidate prompt solutions for a task based on output demonstrations.
- Active prompt—Active-prompt improves CoT methods by dynamically adapting language models to task-specific prompts through a process involving query, uncertainty analysis, human annotation, and enhanced inference.
- ReAct prompting—ReAct integrates LLMs for concurrent reasoning traces and task-specific actions, improving performance by interacting with external tools for information retrieval. When combined with CoT, it optimally utilizes internal knowledge and external information, enhancing the interpretability and trust worthiness of LLMs.
- Recursive prompting—Recursive prompting breaks down complex problems into subproblems, solving them by sequentially using prompts. This method aids compositional generalization in tasks such as math problems or question answering, with the model building on solutions from previous steps.
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Selecting the first chunk as the retrieved information
retrieved_context= retrieved_docs[0].page_content
# Creating the prompt
augmented_prompt=f"""
Given the context below, answer the question.
Question: {query}
Context : {retrieved_context}
Remember to answer only based on the context provided and not from any other
source.
If the question cannot be answered based on the provided context, say I don't
know.
"""
Generation
Criteria for choosing between foundation and fine-tuned models 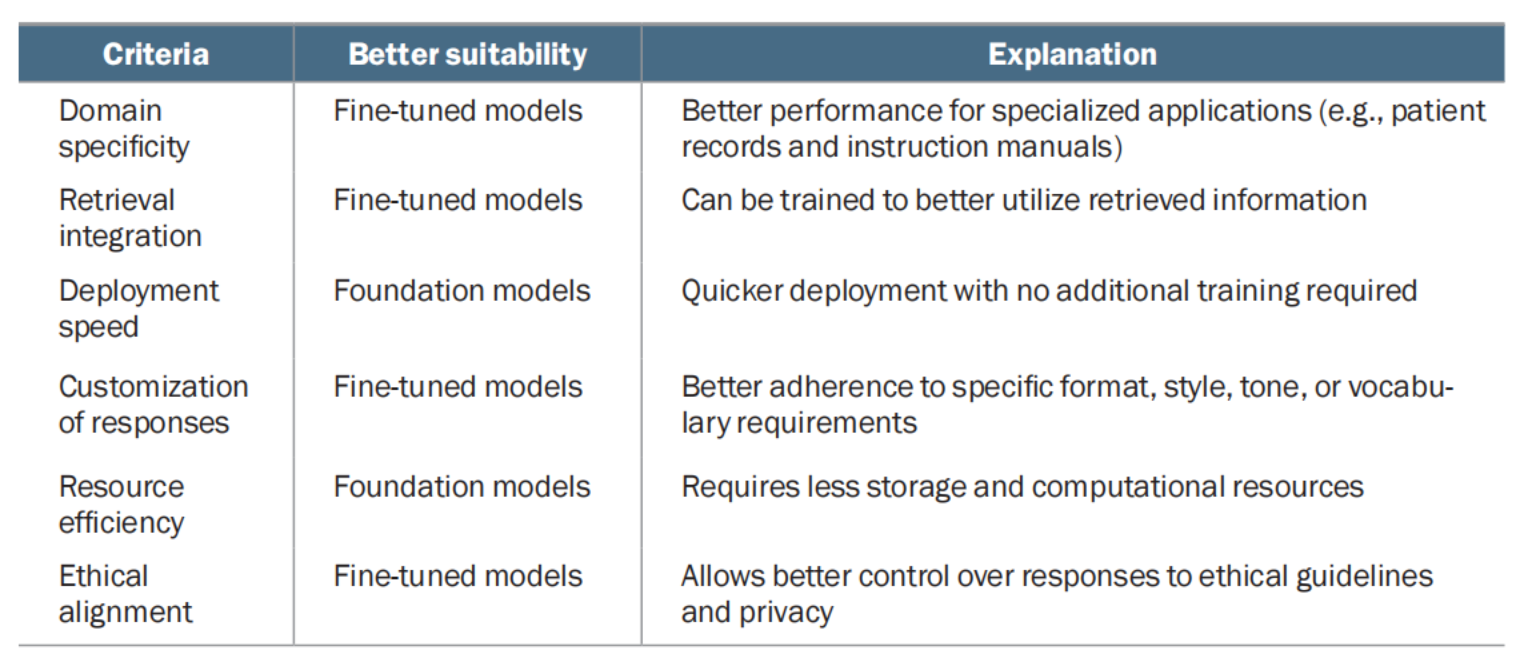 Criteria for choosing between open source and proprietary models
Criteria for choosing between open source and proprietary models 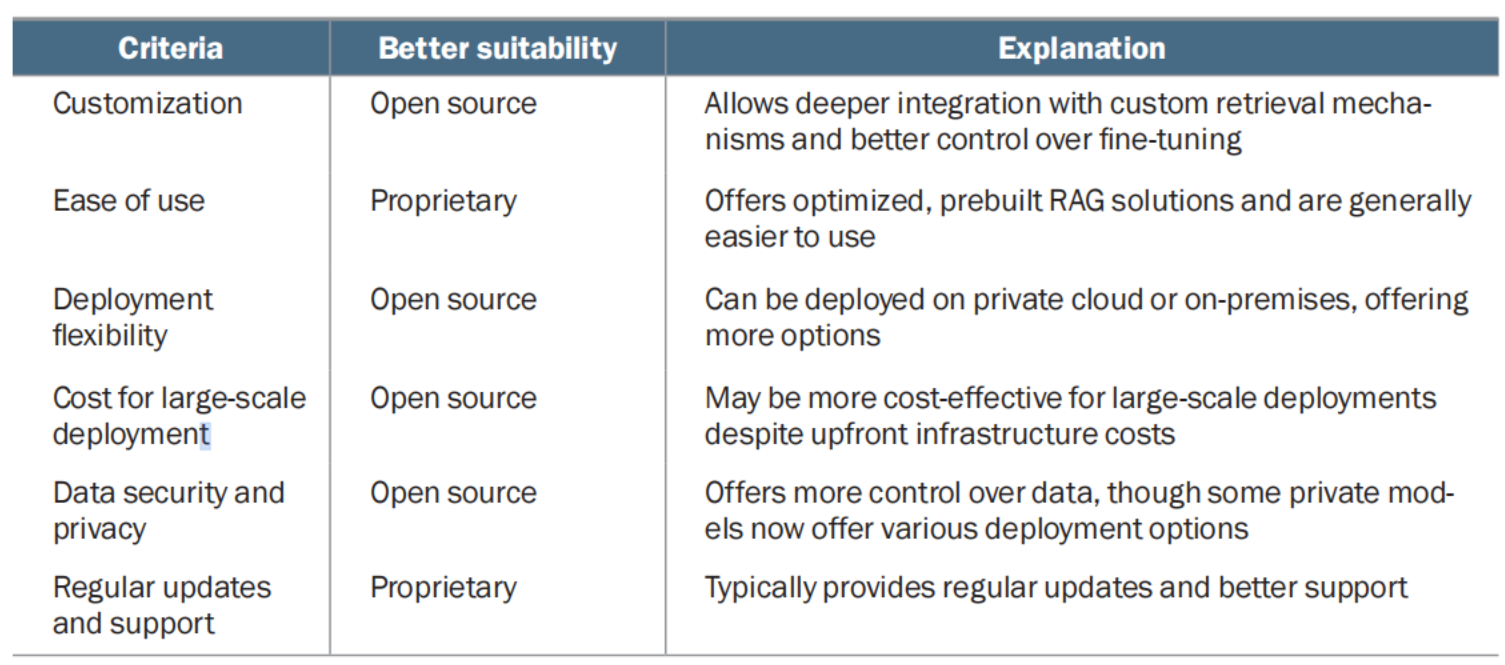 Criteria for choosing between small and large models
Criteria for choosing between small and large models 
code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Importing the OpenAI library from langchain
from langchain_openai import ChatOpenAI
# Instantiate the OpenAI LLM
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2
)
# Make the API call passing the augmented prompt to the LLM
response = llm.invoke (
[("human",augmented_prompt)]
)
# Extract the answer from the response object
answer=response.content
print(answer)
Summary
Retrieval
- Retrieval is the process of finding relevant information from the knowledge base based on a user query. It is a search problem to match documents with input queries.
- The popular retrieval methods for RAG include
- TF-IDF (Term Frequency-Inverse Document Frequency)—Statistical measure of word importance in a document relative to a corpus. It can be implemented using LangChain’s TFIDFRetriever.
- BM25 (Best Match 25)—Advanced probabilistic model, an improvement over TF-IDF. It adjusts for document length and can be implemented using LangChain’s BM25Retriever.
- Static word embeddings—Represent words as dense vectors (e.g., Word2Vec, GloVe) and capture semantic relationships but lack full contextual understanding.
- Contextual embeddings—Produced by models like BERT or OpenAI’s text embeddings. They provide context-aware representations and are most widely used in RAG, despite being computationally intensive.
- Advanced retrieval methods—They include learned sparse retrieval, dense retrieval, hybrid retrieval, cross-encoder retrieval, graph-based retrieval, quantum-inspired retrieval, and neural IR models.
- Most advanced implementations will include a hybrid approach.
- Vector stores and databases (e.g., FAISS, PineCone, Milvus, Weaviate), cloud provider solutions (e.g., Amazon Kendra, Azure AI Search, Google Vertex AI Search), and web information resources (e.g., Wikipedia, Arxiv, AskNews) are some of the popular retriever integrations provided by LangChain.
- The choice of retriever depends on factors such as accuracy, speed, and compatibility with the indexing method.
Augmentation
- Augmentation combines the user query with retrieved information to create a prompt for the LLM.
- Prompt engineering is crucial for effective augmentation, aiming for accuracy and relevance in LLM responses.
- Key prompt engineering techniques for RAG include
- Contextual prompting—Adding retrieved information with instructions to focus on the provided context.
- Controlled generation prompting—Instructing the LLM to admit lack of knowledge when information is insufficient.
- Few-shot prompting—Providing examples to guide the LLM’s response format or style.
- Chain-of-thought (CoT) prompting—Introducing intermediate reasoning steps for complex tasks.
- Advanced techniques—These include self-consistency, generated knowledge prompting, and tree of thought.
- The choice of augmentation technique depends on the task complexity, desired output format, and LLM capabilities.
Generation
- Generation is the final step in which the LLM produces the response based on the augmented prompt.
- LLMs can be categorized based on how they’ve been trained, how they can be accessed, and the number of parameters they have.
- Supervised fine-tuning, or SFT, improves context use and domain optimization, enhances coherence, and enables source attribution; however, it comes with challenges such as cost, risk of overreliance on retrieval, and potential tradeoffs with inherent LLM abilities.
- The choice between open source and proprietary LLMs depends on customization needs, long-term costs, and data sensitivity.
- Larger models come with superior reasoning, language understanding, and broader knowledge, and generate more coherent and contextually accurate responses but come with high computational and resource requirements. Smaller models allow faster inference, lower resource usage, and are easier to deploy on edge devices or resource-constrained environments but do not have the same language understanding abilities as large models.
- Popular LLMs include offerings from OpenAI, Anthropic, Google, and similar, and open source models are available through platforms such as Hugging Face.
- The choice of LLM depends on factors such as performance requirements, resource constraints, deployment environment, and data sensitivity.
- The choice of LLM for RAG systems requires careful consideration, experimentation, and potential adaptation based on performance.