Indexing pipeline
Creating a knowledge base for RAG
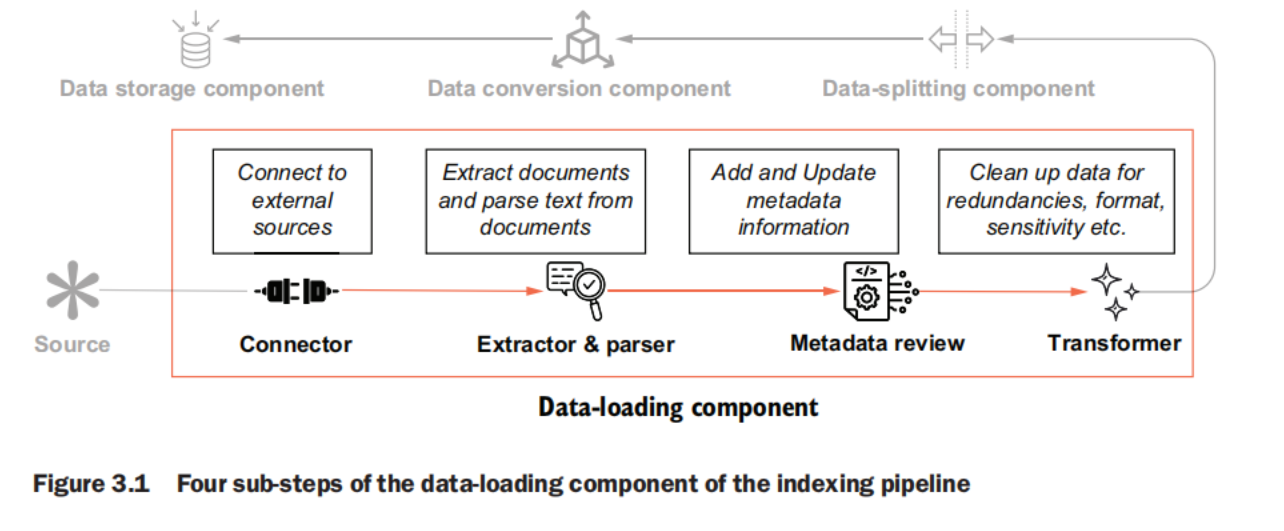
data loading
Although data loading may seem simple (after all, it’s just connecting to a source and extracting data), the nuances of adding metadata, document transformation, masking, and similar add complexity to this step. Advanced planning of the sources, a review of the formats, and curation of metadata information are advised for best results.
- Connect to the source of data.
- Extract text from the file.
- Review and update metadata information.
- Clean or transform the data.
data splitting (chunking)
advantages
When it comes to overcoming the major limitations of using long pieces of text in LLM applications, chunking offers the following three advantages:
- Context window of LLMs—Due to the inherent nature of the technology, the number of tokens LLMs can work with at a time is limited. This includes both the number of tokens in the prompt and in the completion (or the output). The limit on the total number of tokens that an LLM can process in one go is called “the context window size.” If we pass an input that is longer than the context window size, the LLM chooses to ignore all text beyond the size. It is thus very important to be careful with the amount of text being passed to the LLM. In our example, a text of 50,000 words will not work well with LLMs that have a smaller context window. The way to address this problem is to break the text down into smaller chunks.
- Lost-in-the-middle problem—Even in those LLMs that have a long context window (e.g., Claude 3 by Anthropic has a context window of up to 200,000 tokens), a problem with accurately reading the information has been observed. It has been noticed that accuracy declines dramatically if the relevant information is some where in the middle of the prompt. This problem can be addressed by passing only the relevant information to the LLM instead of the entire document.
- Ease of search—This is not a problem with the LLM per se, but it has been observed that large chunks of text are harder to search over. When we use a retriever, it is more efficient to search over smaller pieces of text.
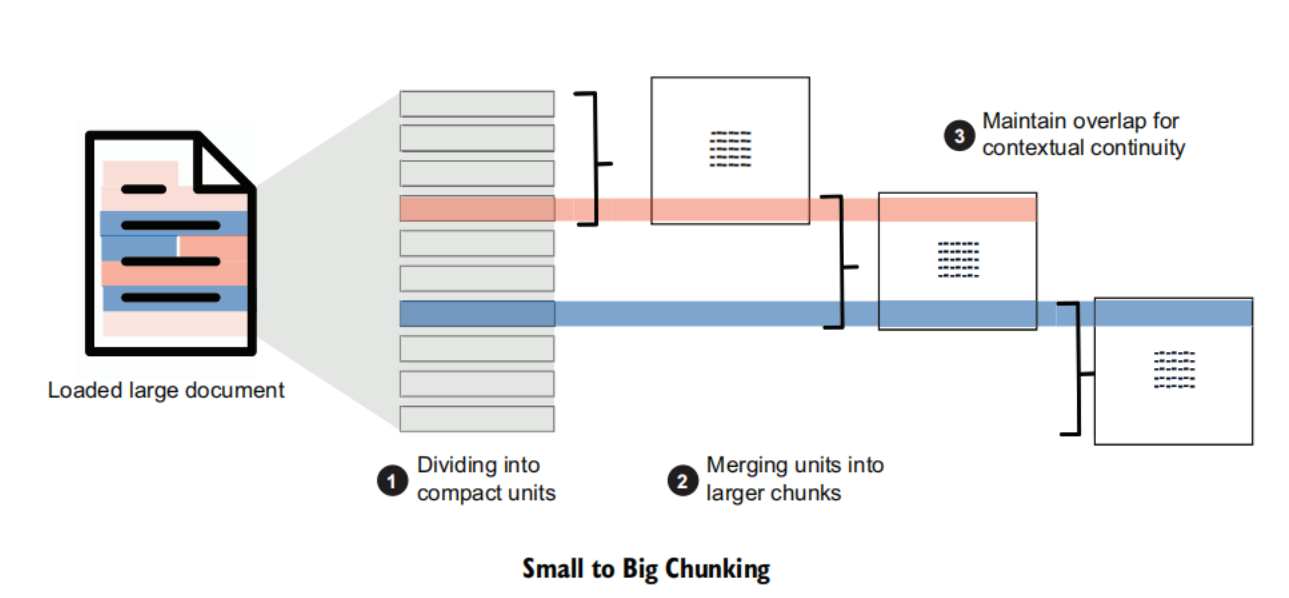
small to big chunking
- Divide the longer text into compact, meaningful units (e.g., sentences or paragraphs).
- Merge the smaller units into larger chunks until a specific size is achieved. After that, this chunk is treated as an independent segment of text.
- When creating a new chunk, include a part of the previous chunk at the start of the new chunk. This overlap is necessary to maintain contextual continuity.
chunking methods
- The manner of text splitting
- Measuring of the chunk size
Fixed-Sized Chunking
Predetermine the size of the chunk and the amount of overlap between the chunks.
drawback
The limitation of fixed-size chunking is that it doesn’t consider the semantic integrity of the text. In other words, the meaning of the text is ignored. It works best in scenarios where data is inherently uniform, such as genetic sequences and service manuals, or uniformly structured reports such as survey responses.
- Split by character—Here, we specify a certain character, such as a newline character \n or a special character *, to determine how the text should be split.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#import libraries
from langchain.text_splitters import CharacterTextSplitter
#Set the CharacterTextSplitter parameters
text_splitter = CharacterTextSplitter(
separator="\n", #The character that should be used to split
chunk_size=1000, #Number of characters in each chunk
chunk_overlap=200, #Number of overlapping characters between chunks
)
#Create Chunks
chunks=text_splitter.create_documents(
[html_data_transformed[0].page_content]
)
#Show the number of chunks created
print(f"The number of chunks created : {len(chunks)}")
>>The number of chunks created: 67
However, sometimes, it may not be feasible to create chunks within the specified length. This is because the sequential occurrence of the character on which the text needs to be split is far apart. To address this problem, a recursive approach is employed.
- Recursively split by character—This method is quite like the split by character but instead of specifying a single character for splitting, we specify a list of characters. The approach initially tries creating chunks based on the first character. In case it is not able to create a chunk of the specified size using the first character, it then uses the next character to further break down chunks to the required size. This method ensures that chunks are largely created within the specified size. This method is recommended for generic texts.
1 2 3 4 5
text_splitter = RecursiveCharacterTextSplitter( separator=["\n\n","\n", ".", " "], #The character that should be used to split chunk_size=1000, #Number of characters in each chunk chunk_overlap=200, #Number of overlapping characters between chunks )
- split by token — Here, the splitting still happens based on a character, but the size of the chunk and the overlap are determined by the number of tokens instead of the number of characters.
1 2
CharacterTextSplitter.from_tiktoken_encoder(encoding="cl100k_base", chunk_size=100, chunk_overlap=10) CharacterTextSplitter.from_huggingface_tokenizer(tokenizer, chunk_size=100, chunk_overlap=10)
Specialized chunking
If we are dealing with data in the form of HTML, Markdown, JSON, or even computer code, it makes more sense to split the data based on the structure rather than a fixed size. Another approach to chunking is to consider the format of the extracted and loaded data. A markdown file, for example, is organized by headers, a code written in a programming language such as Python or Java is organized by classes and functions, and likewise, HTML is organized in headers and sections.
advantage
Specialized chunking works well in structured scenarios such as customer reviews or patient records where data can be of different lengths but should ideally be in the same chunk.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Import the HTMLHeaderTextSplitter library
from langchain_text_splitters import HTMLSectionSplitter
# Set URL as the Wikipedia page link
url="https://en.wikipedia.org/wiki/2023_Cricket_World_Cup"
loader = AsyncHtmlLoader (url)
html_data = loader.load()
# Specify the header tags on which splits should be made
sections_to_split_on=[
("h1", "Header 1"),
("h2", "Header 2"),
("table ", "Table"),
("p", "Paragraph")
]
# Create the HTMLHeaderTextSplitter function
splitter = HTMLSectionSplitter(sections_to_split_on)
# Create splits in text obtained from the URL
Split_content = splitter.split_text(html_data[0].page_content)
Chunking methods do not have to be exclusive. We can further chunk these 231 chunks using a fixed-size chunking method such as RecursiveCharacterTextSplitter.
1
2
3
4
5
6
7
8
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n","\n","."]
chunk_size=1000, chunk_overlap=100,
)
final_chunks = text_splitter.split_documents(split_content)
Semantic chunking
A method that looks at semantic similarity (or similarity in the meaning) between sentences is called semantic chunking. It first creates groups of three sentences and then merges groups that are similar in meaning. To find out the similarity in meaning, this method uses embeddings. 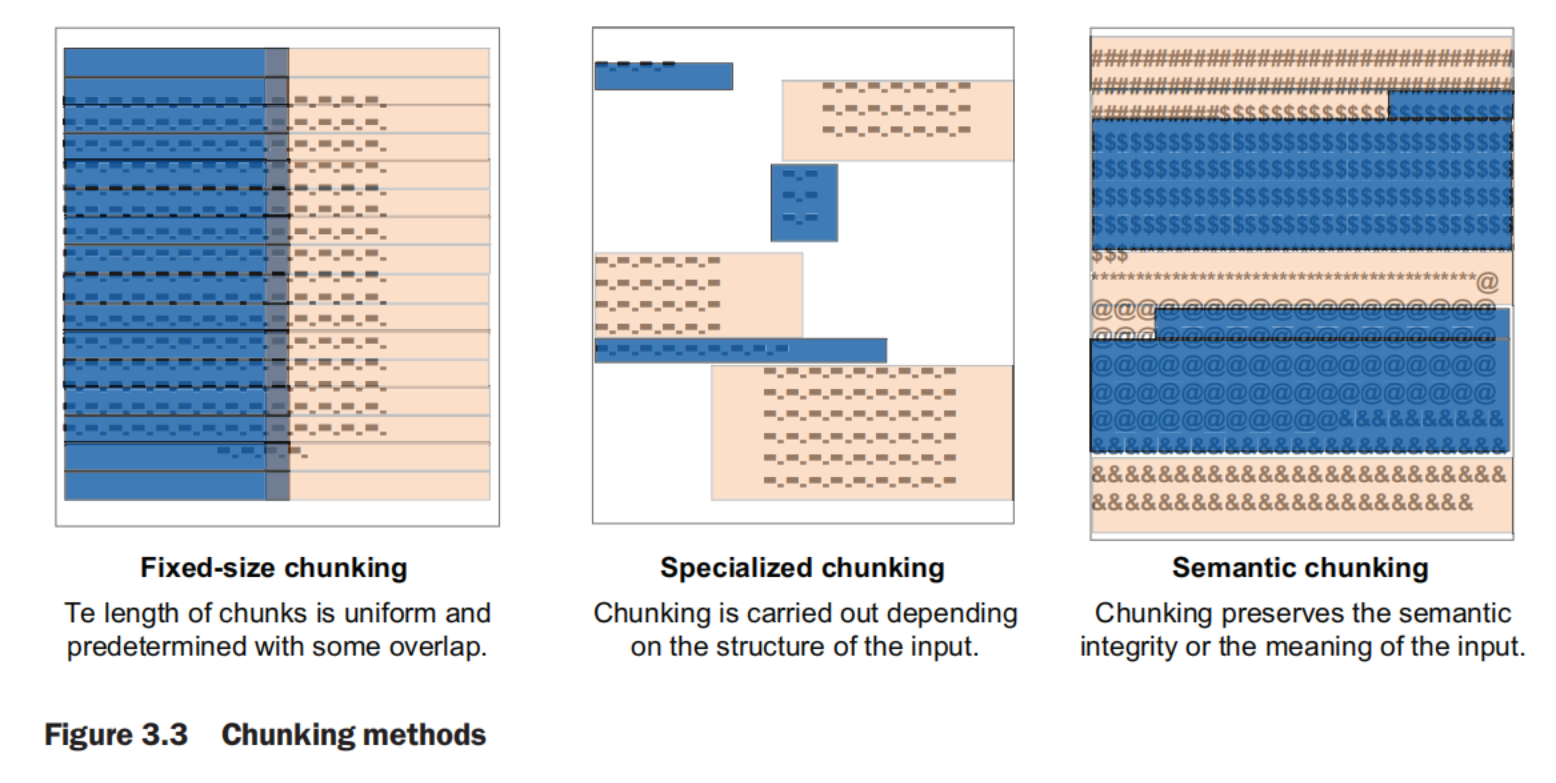
choosing chunking strategy
- Nature of the content. The type of data that you’re dealing with can be a guide for the chunking strategy. If you’re using a diverse set of information sources, then you might have to use different methods for different sources.
- Expected length and complexity of user query. The nature of the query that your RAG system is likely to receive also determines the chunking strategy. If your system expects a short and straightforward query, then the size of your chunks should be different when compared to a long and complex query. Matching long queries to short chunks may prove inefficient in certain cases. Similarly, short queries matching large chunks may yield partially irrelevant results.
- Application and use case requirements. The nature of the use case you’re addressing may also determine the optimal chunking strategy. For a direct question-answering system, shorter chunks are likely used for precise results, while for summarization tasks, longer chunks may make more sense. If the results of your system need to serve as an input to another downstream application, that may also influence the choice of the chunking strategy.
- Embeddings model. Certain embeddings models perform better with chunks of specific sizes.
Data Conversion (embeddings)
The goal of an embedding model is to convert words (or sentences/paragraphs) into n-dimensional vectors so that the words (or sentences/paragraphs) that are like each other in meaning lie close to each other in the vector space. 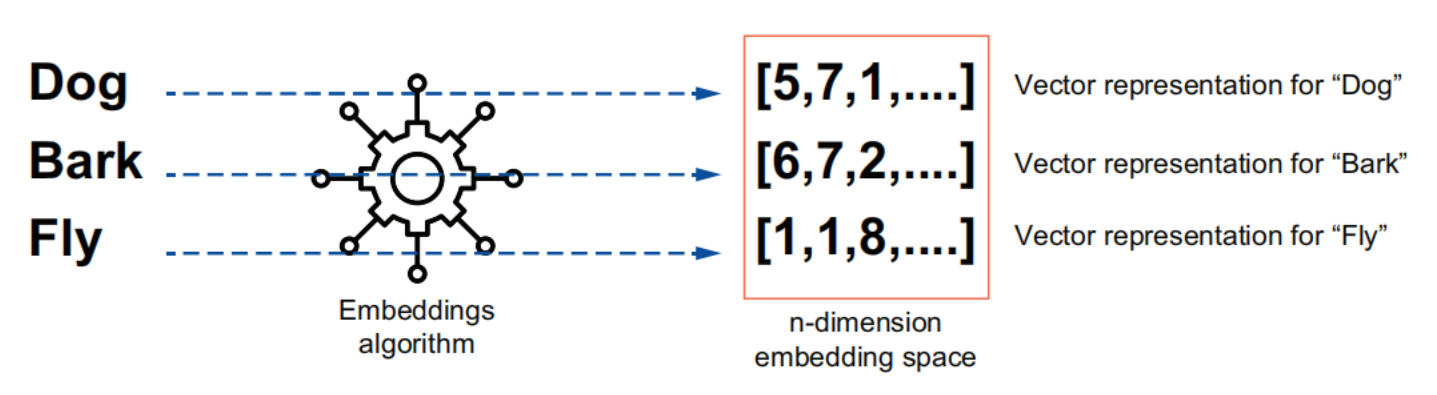
Embedding Algorithm
An embeddings model can be trained on a corpus of preprocessed text data using an embedding algorithm such as Word2Vec, GloVe, FastText, or BERT:
- Word2Vec—Word2Vec is a shallow-neural-network-based model for learning word embeddings, developed by researchers at Google. It is one of the earliest embedding techniques.
- GloVe—Global Vectors for Word Representations is an unsupervised learning technique developed by researchers at Stanford University.
- FastText—FastText is an extension of Word2Vec developed by Facebook AI Research. It is particularly useful for handling misspellings and rare words.
- ELMo—Embeddings from Language Models was developed by researchers at Allen Institute for AI. ELMo embeddings have been shown to improve performance on question answering and sentiment analysis tasks.
- BERT—Bidirectional Encoder Representations from Transformers, developed by researchers at Google, is a transformers-architecture-based model. It provides contextualized word embeddings by considering bidirectional context, achieving state-of-the-art performance on various NLP tasks.
Common pre-trained embeddings models
- Embeddings models by OpenAI
- text-embedding-ada-002: It converts text into a vector of 1536 dimensions.
- text-embedding-3-small: Users can adjust the size of the dimensions according to their needs.
- text-embedding-3-large: 3072 dimensions
- Voyage AI—These embeddings models are recommended by Anthropic. Voyage offers several embedding models such as:
- voyage-large-2-instruct is a 1024-dimensional embeddings model that has become a leader in embeddings models.
- voyage-law-2 is a 1024-dimension model optimized for legal documents.
- voyage-code-2 is a 1536-dimension model optimized for code retrieval.
- voyage-large-2 is a 1536-dimension general-purpose model optimized for retrieval.
 MTEB Leaderboard - a Hugging Face Space by mtebEmbedding Leaderboard
MTEB Leaderboard - a Hugging Face Space by mtebEmbedding Leaderboard
Code Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Import HuggingFaceEmbeddings from embeddings library
from langchain_huggingface import HuggingFaceEmbeddings
# Instantiate the embeddings model. The embeddings model_name can be changed as desired
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
# Create embeddings for all chunks
hf_embeddings = embeddings.embed_documents(
[chunk.page_content for chunk in final_chunks]
)
#Check the length(dimension) of the embedding
len(hf_embeddings[0])
>> 768

How to choose
- use case
- cost
Storage
vector database
Vector databases are built to handle high-dimensional vectors. These databases specialize in indexing and storing vector embeddings for fast semantic search and retrieval.
Apart from efficiently storing high-dimensional vector data, modern vector databases offer traditional features such as scalability, security, multi-tenancy, versioning and management, and similar. However, vector databases are unique in offering similarity searches based on Euclidean distance or cosine similarity. They also employ specialized indexing techniques.
- Vector indexes—These are libraries that focus on the core features of indexing and search. They do not support data management, query processing, or interfaces. They can be considered a bare-bones vector database. Examples of vector indexes are Facebook AI Similarity Search (FAISS), Non-Metric Space Library(NMSLIB), Approximate Nearest Neighbors Oh Yeah (ANNOY), Scalable Nearest Neighbors (ScaNN), and similar.
- Specialized vector DBs—These databases focus on the core feature of high dimensional vector support, indexing, search, and retrieval such as vector indexes, but also offer database features such as data management, extensibility, security, scalability, non-vector data support, and similar. Examples of specialized vector DBs are Pinecone, ChromaDB, Milvus, Qdrant, Weaviate, Vald, LanceDB, Vespa, and Marqo.
- Search platforms—Solr, Elastic Search, Open Search, and Apache Lucene are traditional text search platforms and engines built for full text search. They have now added vector similarity search capabilities to their existing search capabilities.
- Vector capabilities for SQL databases—Azure SQL, Postgres SQL(pgvector), SingleStore, and CloudSQL are traditional SQL databases that have now added vector data-handling capabilities.
- Vector capabilities for NoSQL databases—Like SQL DBs, NoSQL DBs such as MongoDB have also added vector search capabilities.
- Graph databases with vector capabilities—Graph DBs such as Neo4j, have also opened new possibilities by adding vector capabilities.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# Install FAISS-CPU
%pip install faiss-cpu==1.10.0 --quiet
# Import FAISS class from vectorstore library
from langchain_community.vectorstores import FAISS
from langchain_community.docstore.in_memory import InMemoryDocstore
# Import OpenAIEmbeddings from the library
from langchain_openai import OpenAIEmbeddings
# Set the OPENAI_API_KEY as the environment variable
import os
os.environ["OPENAI_API_KEY"] = <YOUR_API_KEY>
# Chunks from Section 3.3
Final_chunks=final_chunks
# Instantiate the embeddings object
embeddings=OpenAIEmbeddings(model="text-embedding-3-small")
# Instantiate the FAISS object
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
# Add the chunks
vector_store.add_documents(documents=final_chunks)
# Check the number of chunks that have been indexed
vector_store.index.ntotal
>> 285
# save
vector_store.save_local(folder_path,index_name)
FAISS.load_local(folder_path,index_name)
# Original Question
query = "Who won the 2023 Cricket World Cup?"
# Ranking the chunks in descending order of similarity
docs = vector_store.similarity_search(query)
# Printing one of the top-ranked chunk
print(docs[0].page_content)
choosing vector database
- Accuracy vs. speed—Certain algorithms are more accurate but slower. A balance between search accuracy and query speed must be achieved based on application needs. It will become important to evaluate vector DBs on these parameters.
- Flexibility vs. performance—Vector DBs provide customizations to the user. While it may help you in tailoring the DB to your specific requirements, more customizations can add overhead and slow systems down.
- Local vs. cloud storage—Assess tradeoffs between local storage speed and access versus cloud storage benefits like security, redundancy, and scalability.
- Direct access vs. API—Determine if tight integration control via direct libraries is required or if ease-of-use abstractions like APIs better suit your use case.
- Simplicity vs. advanced features—Compare advanced algorithm optimizations, query features, and indexing versus how much complexity your use case necessitates versus needs for simplicity.
- Cost—While you may incur regular costs in a fully managed solution, a self-hosted one might prove costlier if not managed well.
Summary
Data loading
- The process of sourcing data from its original location is called data loading, and it includes the following four steps: connecting to the source, extracting and parsing text, reviewing and updating metadata, and cleaning and transforming data.
- Loading documents from a list of sources may turn out to be a complicated process. Make sure to plan for all the sources and loaders in advance.
- A variety of data loaders from LangChain can be used.
- Breaking down long pieces of text into manageable sizes is called data splitting or chunking.
- Chunking addresses context window limits of LLMs, mitigates the lost-in-the middle problem for long prompts, and enables easier search and retrieval.
- The chunking process involves dividing longer texts into small units, merging small units into chunks, and including an overlap between chunks to preserve contextual continuity.
- Chunking can be fixed size, specialized (or adaptive), or semantic. Newer chunking methods are constantly being introduced.
- Your choice of the chunking strategy should be based on the nature of the content, expected length and complexity of user query, application use case, and the embeddings model being used.
- A chunking strategy can include multiple methods.
Data conversion
- For processing, text needs to be converted into a numerical format.
- Embeddings are vector representations of data (words, sentences, documents, etc.).
- The goal of an embedding algorithm is to position similar data points close to each other in a vector space.
- Several pre-trained, open source and proprietary, embedding models are available for use.
- Embeddings models enable similarity search. Embeddings can be used for text search, clustering, ML models, and recommendation engines.
- The choice of embeddings is largely based on the use case and the cost implications.
- Vector databases are designed to efficiently store and retrieve high-dimensional vector data such as embeddings.
- Vector databases provide similarity searches based on distance metrics such as cosine similarity.
- Apart from the similarity search, vector databases offer traditional services such as scalability, security, versioning, and the like.
- Vector capabilities can be offered by standalone vector indexes, specialized vector databases, or legacy offerings such as search platforms, SQL, and NoSQL databases with added vector capabilities.
- Accuracy, speed, flexibility, storage, performance, simplicity, access, and cost are some of the factors that can influence the choice of a vector database.