RAG systems and their design
Outline
- The concept and design of RAG systems
- An overview of the indexing pipeline
- An overview of the generation pipeline
- An initial look at RAG evaluation
- A high-level look at the RAG operations stack
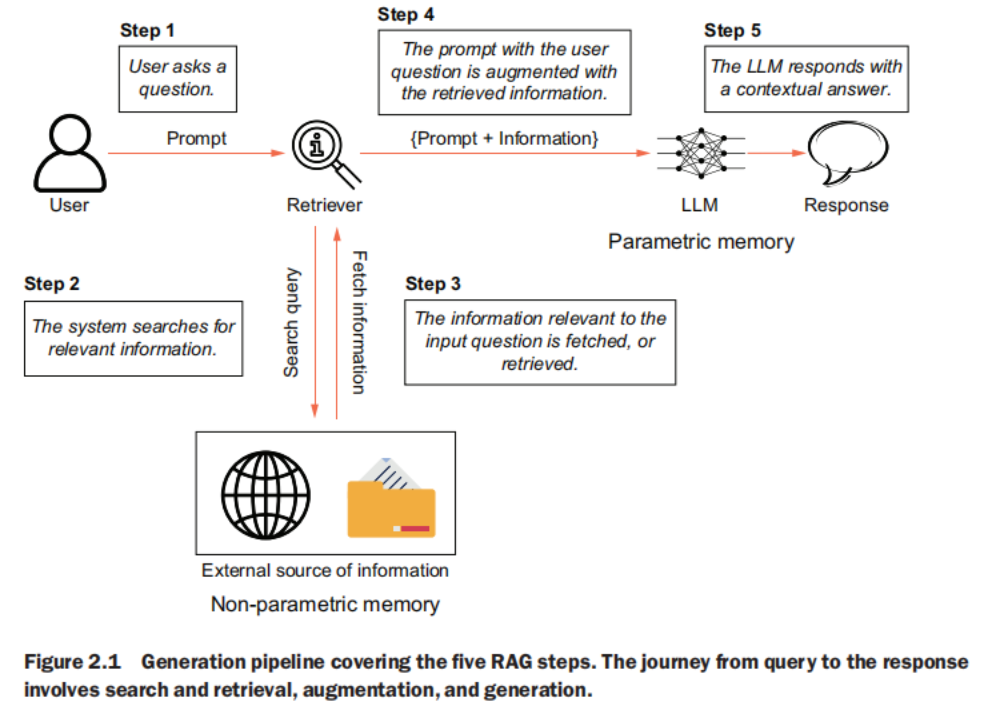
generation pipeline
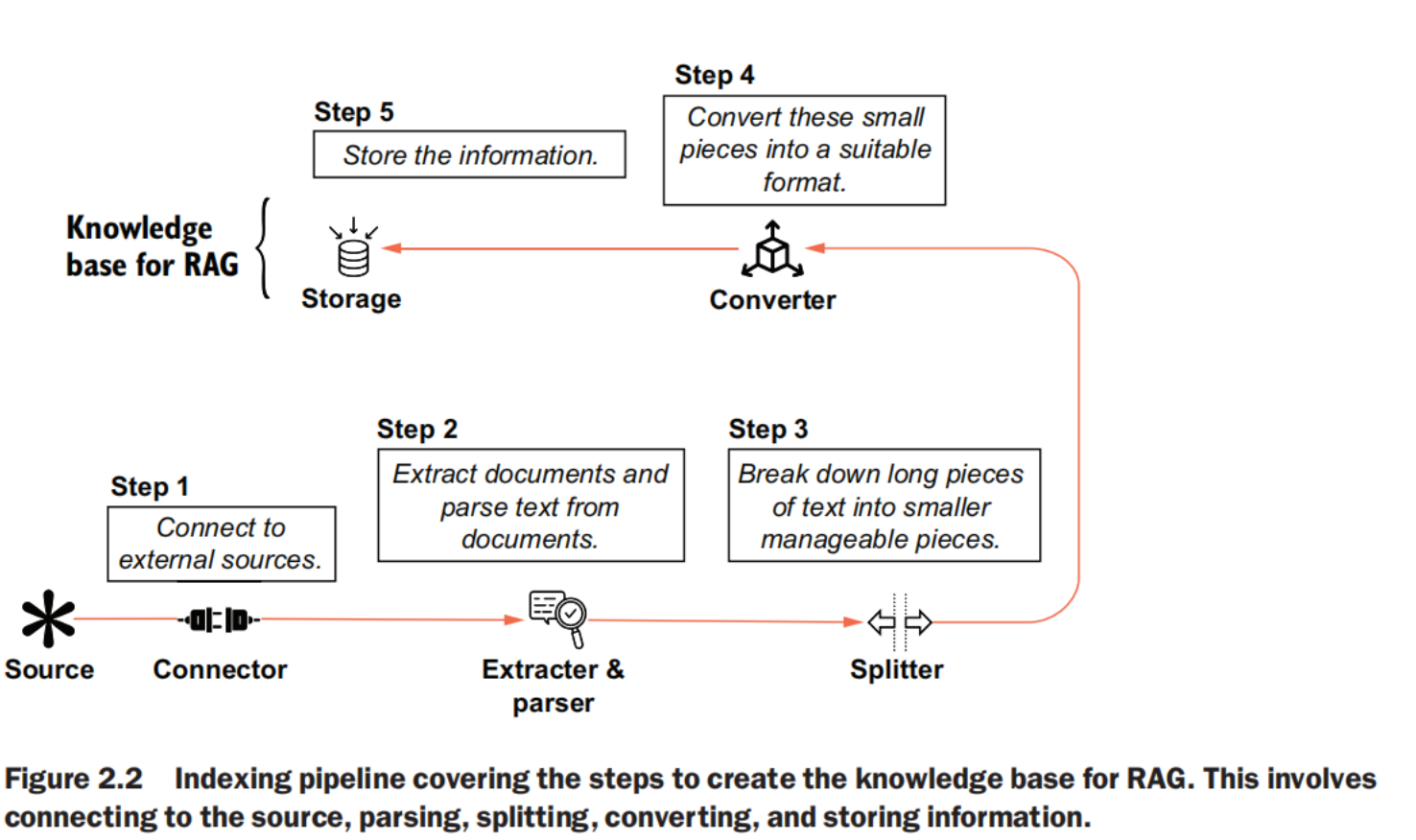
indexing pipeline
steps
- Connect to previously identified external sources.
- Extract documents and parse text from them.
- Break down long pieces of text into smaller, manageable pieces.
- Convert these small pieces into a suitable format.
- Store this information.
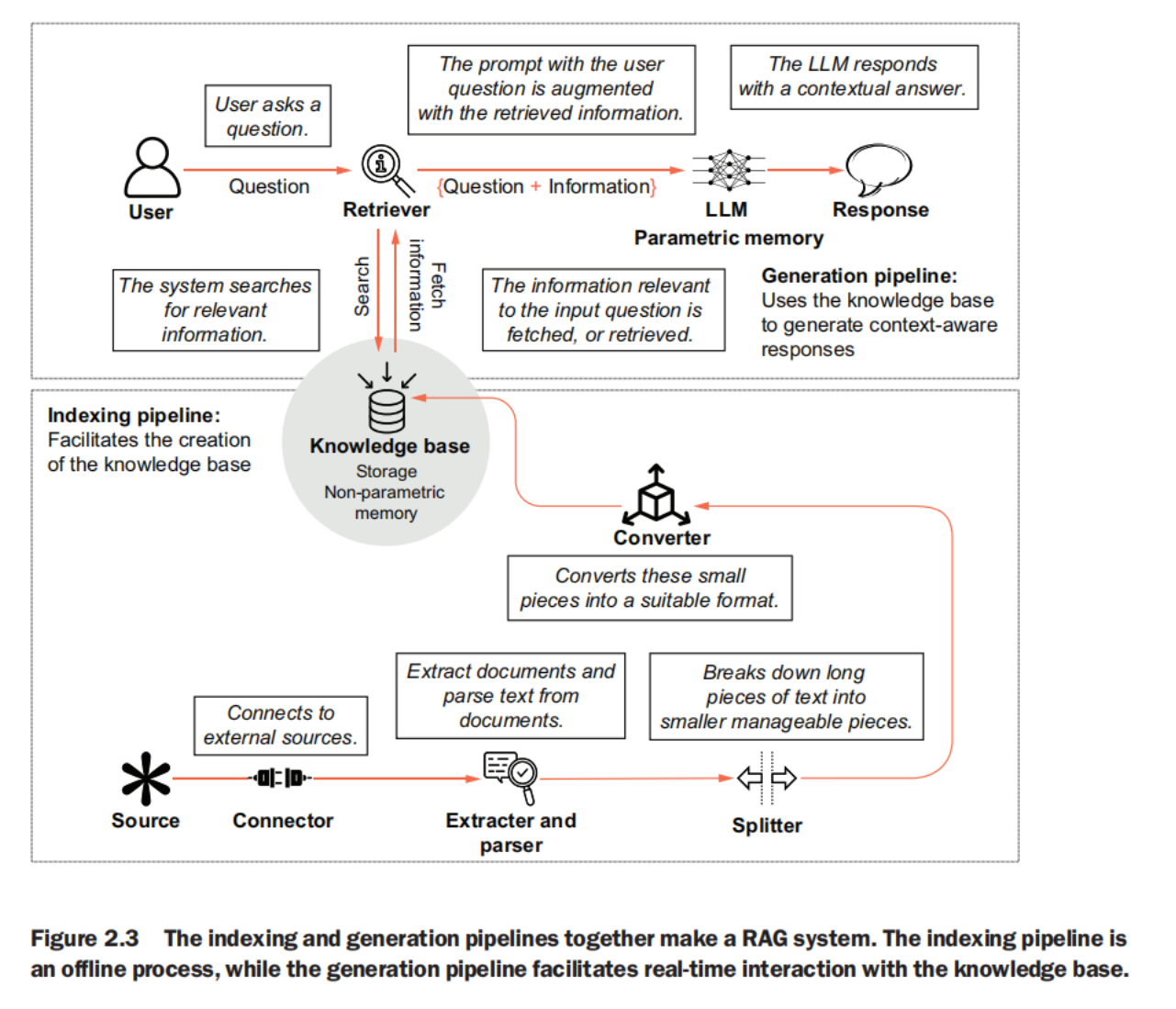
together
production
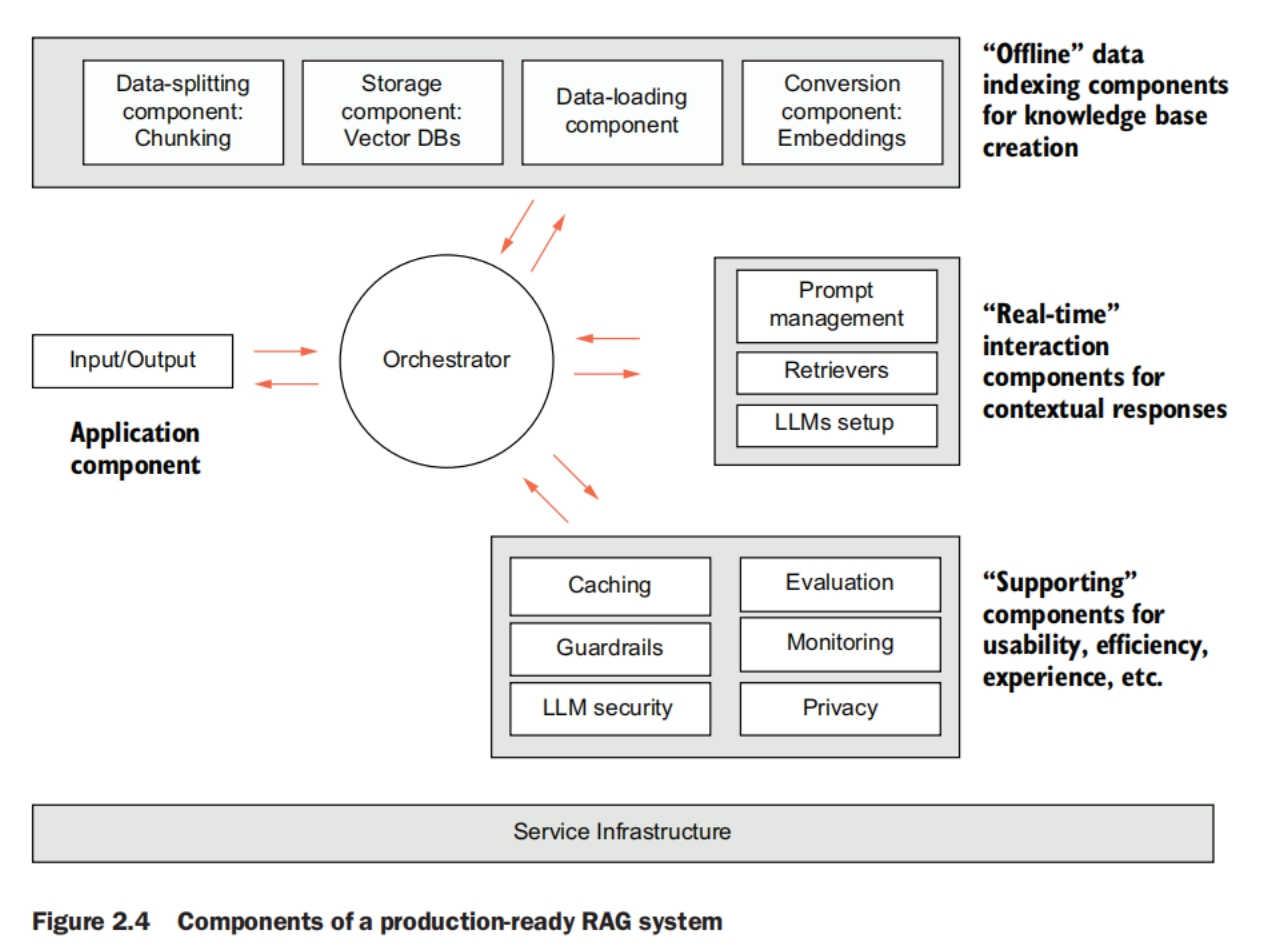
indexing pipeline components
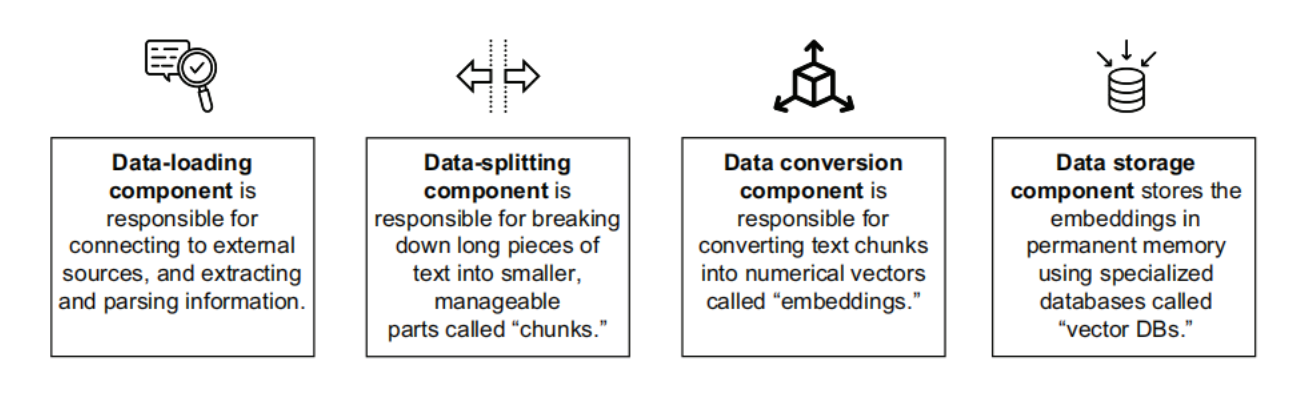
Data-loading component
Connects to external sources, and extracts and parses data. These external sources can be filesystems, data lakes, content management systems, and so forth. The files received from the sources can be in various formats such as PDF, docs, JSON, HTML, and more.
This component, therefore, comprises several connectors (for different external sources), extractors, and parsers (for different file types). The data-loading component also involves efficient preprocessing of data for knowledge consistency, removal of irrelevant information and masking of confidential data. Metadata information is another aspect the data-loading component manages.
Data-splitting component
Breaks down large pieces of text into smaller, manageable parts. Breaking down text into smaller segments enhances the system’s ability to process and analyze information efficiently. These smaller pieces in natural language processing (NLP) parlance are commonly referred to as “chunks.” The process of splitting large text documents into smaller chunks is called “chunking.”
Data conversion component
Converts text data into a more suitable format. Textual data must be converted to a numerical format for search and retrieval computations in RAG systems. There are different ways of implementing this conversion. For all practical purposes, a data format called “embeddings” works best for search and retrieval.
Storage component—Stores the data to create a knowledge base for the system
Once the data is ready in the desired format (embeddings), it needs to be stored in persistent (permanent) memory so that the real-time generation pipeline can access data whenever a user asks a question. Data is stored in specialized databases known as “vector databases,” which are best suited for search and retrieval of embeddings.
generation pipeline components
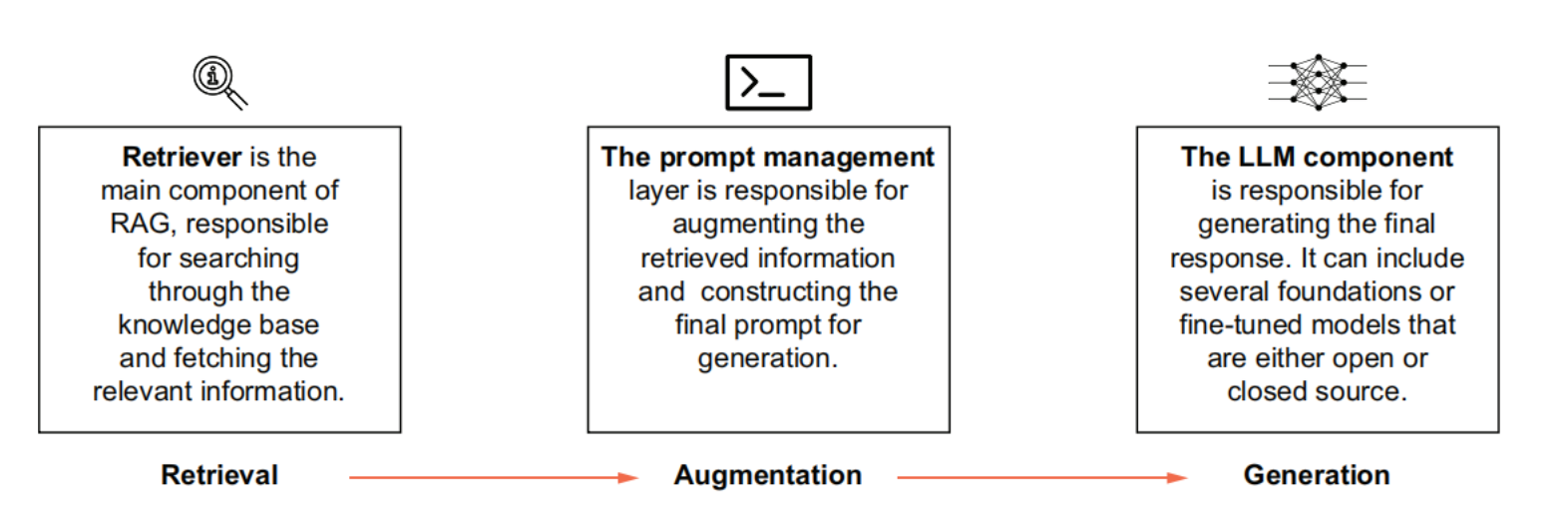
Retrievers
Responsible for searching and fetching information from the storage. This is arguably the most critical component of the entire system. Using advanced search algorithms, the retriever scans the knowledge base to identify and retrieve the most relevant information based on the user’s query. The overall effectiveness of the entire system relies heavily on the accuracy of the retriever. Also, search is a computationally heavy operation and may take time.Therefore, the retriever also contributes heavily to the overall latency of the system.
LLM setup
Responsible for generating the response to the input. The construction of the prompt makes significant difference to the quality of the generated response. This component also falls in the gambit of prompt engineering.
Prompt management
Enables the augmentation of the retrieved information to the original input. At the end, LLMs are responsible for generating the final response. A RAG system may rely on more than one LLM.
supporting components
evaluation component
measures the accuracy and reliability of the system before and after deployment.  What is the RAG Triad? - TruEraThe RAG triad is composed of context relevance, groundedness and answer relevance and helps you evalute RAGs for hallucinations.
What is the RAG Triad? - TruEraThe RAG triad is composed of context relevance, groundedness and answer relevance and helps you evalute RAGs for hallucinations. truera.com
truera.com
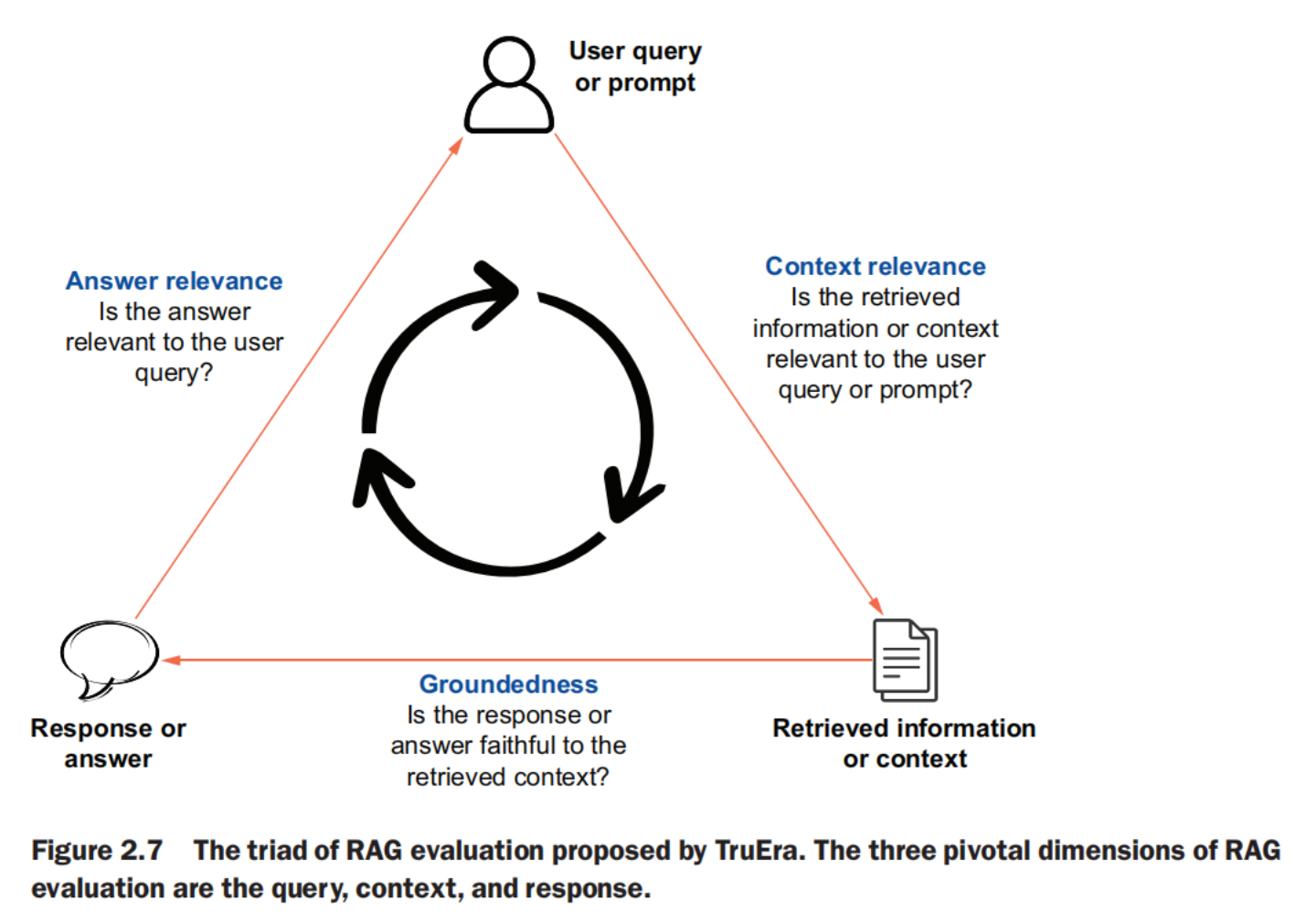
- Between the retrieved information (context) and the user query (prompt)—Is the information being searched and retrieved by the retriever the most relevant to the question the user has asked? The consequence of irrelevant information being retrieved is that no matter how good the LLM is, if the information being augmented is not good, the response will be suboptimal.
- Between the final response (answer) and the retrieved information (context)—Does the LLM consider all the retrieved information while generating responses? Eventhough RAG is aimed at reducing hallucinations, the system might still ignore the retrieved information.
- Between the final response (answer) and the user query (prompt)—Is the final response in line with the question the user had originally asked? To assess the overall effectiveness of the system, the relevance of the final response to the original question is necessary.
monitoring component
Tracks the performance of the RAG system and helps detect failures.
caching component
Store previously generated responses to expedite retrieval for similar queries. Caching is the process in which certain data is stored in cache memory for faster retrieval. LLM caching is slightly different from regular caching. The LLM responses to queries are stored in a semantic cache. Next time a similar query is asked, the response from the cache is retrieved instead of sending the query through the complete RAG pipeline. This approach improves the performance of the system by reducing the time it takes to respond, the cost of LLM inferencing, and the load on the LLM service.
guardrails
Ensure compliance with policy, regulation, and social responsibility. For several use cases, in practice, there will be a set of boundaries within which the output needs to be generated. Guardrails are a predefined set of rules added in the system to comply with policies, regulations, and ethical guidelines.
security
Protect LLMs against breaches such as prompt injection, data poisoning, and so on. LLMs and LLM-based applications have witnessed new threats, such as prompt injections, data poisoning, sensitive information disclosure, and others. With evolving threats, the security infrastructure also needs to evolve to address concerns around security and data privacy of RAG systems.
RAGOps Stack
RAG, and LLM-based apps in general, are being powered by an evolving operations stack. Various providers offer infrastructure components such as data storage platforms, model hosting services, and application orchestration frameworks. The infrastructure can be understood in several layers:
- Data layer—Tools and platforms used to process and store data in the form of embeddings
- Model layer—Providers of proprietary or open source LLMs
- Prompt layer—Tools offering maintenance and evaluation of prompts
- Evaluation layer—Tools and frameworks providing evaluation metrics for RAG
- App orchestration—Frameworks that facilitate invocation of different components of the system
- Deployment layer—Cloud providers and platforms for deploying RAG apps
- Application layer—Hosting services for RAG apps
- Monitoring layer—Platforms offering continuous monitoring of RAG apps
Summary
- A RAG-enabled system consists of two main pipelines: the indexing and the generation pipeline.
- The indexing pipeline is responsible for creating and maintaining the knowledge base, which involves data loading, text splitting, data conversion (embeddings), and data storage in a vector database.
- The generation pipeline manages real-time interactions by retrieving information, augmenting queries, and generating responses using an LLM.
- Evaluation and monitoring are crucial components for the assessment of system performance, covering the relevance between the retrieved information and query, the final response and retrieved information, and the final response and the original query.
- The service infrastructure for RAG systems includes layers for data, models, prompts, evaluation, app orchestration, deployment, application hosting, and monitoring.
- Additional components such as caching, guardrails, and security measures are often employed to improve performance, ensure compliance, and address potential threats.